在線選品優(yōu)化(Online assortment optimization)是近年來運(yùn)營管理領(lǐng)域中備受關(guān)注的重要研究方向。其核心在于探討平臺如何從有限的產(chǎn)品庫存中精心挑選出一組最優(yōu)的產(chǎn)品組合(即“選品”),并將其推薦給隨著時(shí)間陸續(xù)到達(dá)的多樣化客戶群體,以實(shí)現(xiàn)在特定時(shí)間段內(nèi)的平臺總收益最大化。眾多現(xiàn)實(shí)場景,例如酒店預(yù)訂、演出票銷售以及短生命周期產(chǎn)品的推薦等,均可被建模為在線選品優(yōu)化問題。然而,現(xiàn)有主流模型驅(qū)動方法(如離散選擇模型)的模型假設(shè)通常存在局限性,與真實(shí)用戶行為不符,且在相應(yīng)的高維動態(tài)規(guī)劃問題求解中計(jì)算代價(jià)顯著。
圖1 在線選品優(yōu)化(以酒店預(yù)訂為例)
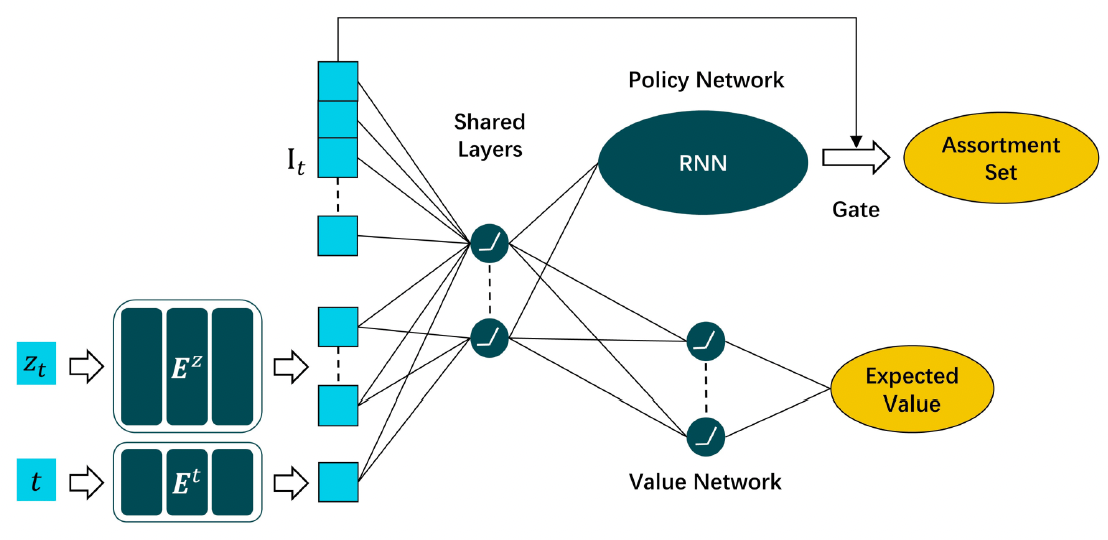
為解決上述難題,西安交通大學(xué)管理學(xué)院智能決策與機(jī)器學(xué)習(xí)研究中心王堯教授與其碩士研究生李韜(現(xiàn)為香港科技大學(xué)博士生)、王晨浩(即將入職同濟(jì)大學(xué)),聯(lián)合美國紐約州立大學(xué)布法羅分校唐少杰(Shaojie Tang)教授和加拿大多倫多大學(xué)陳寧遠(yuǎn)(Ningyuan Chen)教授開展了全新的基于人工智能技術(shù)的研究策略,提出了一種無模型(Model-free)的深度強(qiáng)化學(xué)習(xí)(Deep reinforcement learning)方法。該方法通過使用一個(gè)特別設(shè)計(jì)的深度神經(jīng)網(wǎng)絡(luò)(DNN)來構(gòu)建選品策略,并利用從歷史交易數(shù)據(jù)構(gòu)建的模擬器,通過優(yōu)勢演員-評論家(A2C)算法更新DNN的網(wǎng)絡(luò)參數(shù),以有效解決傳統(tǒng)強(qiáng)化學(xué)習(xí)訓(xùn)練需要大量、甚至不切實(shí)際的交易數(shù)據(jù)的問題。
圖2 本文構(gòu)建的DNN架構(gòu)
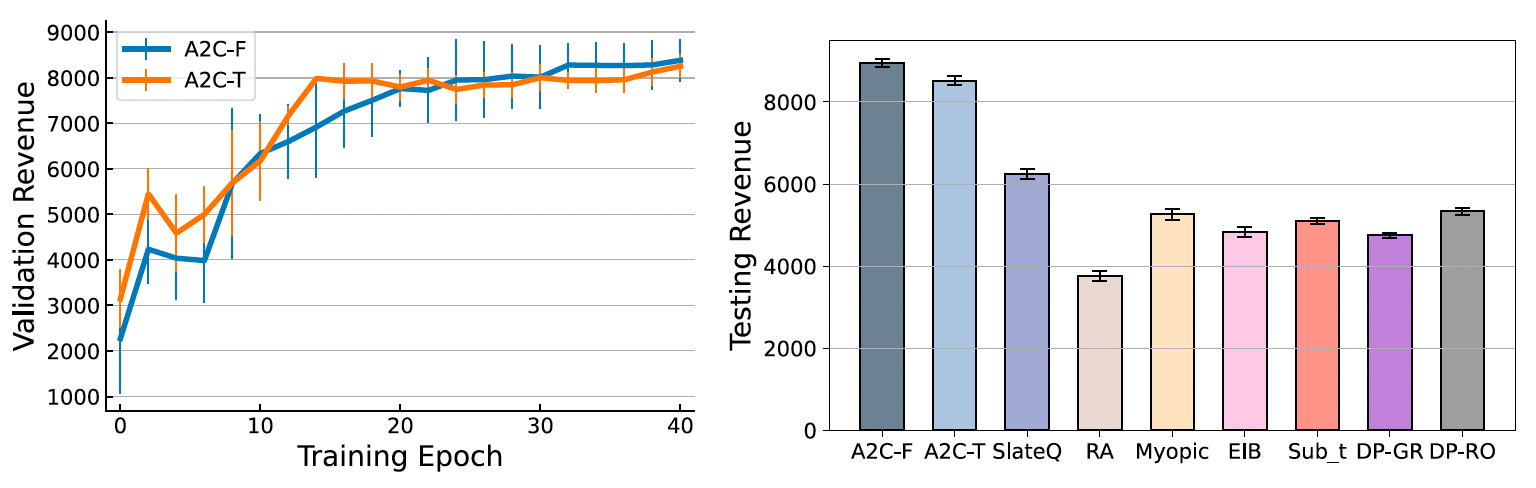
一系列合成數(shù)據(jù)與實(shí)際數(shù)據(jù)上的實(shí)驗(yàn)結(jié)果表明,與主流方法相比,所提方法能夠顯著提高長期收益,并且在各種實(shí)際條件下保持穩(wěn)健性。研究還證明了新方法的靈活性,即可以進(jìn)一步考慮客戶屬性以實(shí)現(xiàn)個(gè)性化策略,并且可通過在DNN的輸入狀態(tài)中增加歷史銷售信息,擴(kuò)展至包含可重復(fù)使用產(chǎn)品的應(yīng)用場景中。
圖3 在Expedia實(shí)際數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果對比
上述研究成果以“基于深度強(qiáng)化學(xué)習(xí)的在線個(gè)性化選品推薦:一種數(shù)據(jù)驅(qū)動的方法”(Deep Reinforcement Learning for Online Assortment Customization: A Data-Driven Approach)為題,于2025年6月在運(yùn)營管理領(lǐng)域頂級期刊《生產(chǎn)與運(yùn)作管理》(Production and Operations Management)在線發(fā)表。李韜博士生、王晨浩博士為論文的共同第一作者,王堯教授為論文的通訊作者,西安交通大學(xué)管理學(xué)院為論文的第一完成單位與通訊單位。該研究得到了國家自然科學(xué)基金面上項(xiàng)目和國家社會科學(xué)基金重大項(xiàng)目的資助。